《Hadoop实战第2版》——1.2节Hadoop项目及其结构
本文共 2943 字,大约阅读时间需要 9 分钟。
1.2 Hadoop项目及其结构
现在Hadoop已经发展成为包含很多项目的集合。虽然其核心内容是MapReduce和Hadoop分布式文件系统,但与Hadoop相关的Common、Avro、Chukwa、Hive、HBase等项目也是不可或缺的。它们提供了互补性服务或在核心层上提供了更高层的服务。图1-1是Hadoop的项目结构图。
下面将对Hadoop的各个关联项目进行更详细的介绍。
1)Common:Common是为Hadoop其他子项目提供支持的常用工具,它主要包括FileSystem、RPC和串行化库。它们为在廉价硬件上搭建云计算环境提供基本的服务,并且会为运行在该平台上的软件开发提供所需的API。2)Avro:Avro是用于数据序列化的系统。它提供了丰富的数据结构类型、快速可压缩的二进制数据格式、存储持久性数据的文件集、远程调用RPC的功能和简单的动态语言集成功能。其中代码生成器既不需要读写文件数据,也不需要使用或实现RPC协议,它只是一个可选的对静态类型语言的实现。Avro系统依赖于模式(Schema),数据的读和写是在模式之下完成的。这样可以减少写入数据的开销,提高序列化的速度并缩减其大小;同时,也可以方便动态脚本语言的使用,因为数据连同其模式都是自描述的。在RPC中,Avro系统的客户端和服务端通过握手协议进行模式的交换,因此当客户端和服务端拥有彼此全部的模式时,不同模式下相同命名字段、丢失字段和附加字段等信息的一致性问题就得到了很好的解决。3)MapReduce:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。映射(Map)、化简(Reduce)的概念和它们的主要思想都是从函数式编程语言中借鉴而来的。它极大地方便了编程人员—即使在不了解分布式并行编程的情况下,也可以将自己的程序运行在分布式系统上。MapReduce在执行时先指定一个Map(映射)函数,把输入键值对映射成一组新的键值对,经过一定处理后交给Reduce,Reduce对相同key下的所有value进行处理后再输出键值对作为最终的结果。图1-2是MapReduce的任务处理流程图,它展示了MapReduce程序将输入划分到不同的Map上、再将Map的结果合并到Reduce、然后进行处理的输出过程。详细介绍请参考本章1.3节。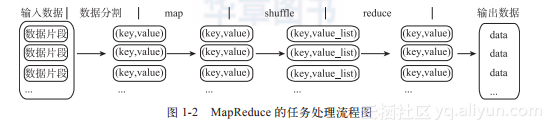
4)HDFS:HDFS是一个分布式文件系统。因为HDFS具有高容错性(fault-tolerent)的特点,所以它可以设计部署在低廉(low-cost)的硬件上。它可以通过提供高吞吐率(high throughput)来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了对可移植操作系统接口(POSIX,Portable Operating System Interface)的要求,这样可以实现以流的形式访问文件系统中的数据。HDFS原本是开源的Apache项目Nutch的基础结构,最后它却成为了Hadoop基础架构之一。
以下几个方面是HDFS的设计目标: 检测和快速恢复硬件故障。硬件故障是计算机常见的问题。整个HDFS系统由数百甚至数千个存储着数据文件的服务器组成。而如此多的服务器则意味着高故障率,因此,故障的检测和快速自动恢复是HDFS的一个核心目标。 流式的数据访问。HDFS使应用程序流式地访问它们的数据集。HDFS被设计成适合进行批量处理,而不是用户交互式处理。所以它重视数据吞吐量,而不是数据访问的反应速度。 简化一致性模型。大部分的HDFS程序对文件的操作需要一次写入,多次读取。一个文件一旦经过创建、写入、关闭就不需要修改了。这个假设简化了数据一致性问题和高吞吐量的数据访问问题。 通信协议。所有的通信协议都是在TCP/IP协议之上的。一个客户端和明确配置了端口的名字节点(NameNode)建立连接之后,它和名字节点的协议便是客户端协议(Client Protocal)。数据节点(DataNode)和名字节点之间则用数据节点协议(DataNode Protocal)。关于HDFS的具体介绍请参考本章1.3节。5)Chukwa:Chukwa是开源的数据收集系统,用于监控和分析大型分布式系统的数据。Chukwa是在Hadoop的HDFS和MapReduce框架之上搭建的,它继承了Hadoop的可扩展性和健壮性。Chukwa通过HDFS来存储数据,并依赖MapReduce任务处理数据。Chukwa中也附带了灵活且强大的工具,用于显示、监视和分析数据结果,以便更好地利用所收集的数据。6)Hive:Hive最早是由Facebook设计的,是一个建立在Hadoop基础之上的数据仓库,它提供了一些用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储的工具。Hive提供的是一种结构化数据的机制,它支持类似于传统RDBMS中的SQL语言的查询语言,来帮助那些熟悉SQL的用户查询Hadoop中的数据,该查询语言称为Hive QL。与此同时,传统的MapReduce编程人员也可以在Mapper或Reducer中通过Hive QL查询数据。Hive编译器会把Hive QL编译成一组MapReduce任务,从而方便MapReduce编程人员进行Hadoop系统开发。7)HBase:HBase是一个分布式的、面向列的开源数据库,该技术来源于Google论文《Bigtable:一个结构化数据的分布式存储系统》。如同Bigtable利用了Google文件系统(Google File System)提供的分布式数据存储方式一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase不同于一般的关系数据库,原因有两个:其一,HBase是一个适合于非结构化数据存储的数据库;其二,HBase是基于列而不是基于行的模式。HBase和Bigtable使用相同的数据模型。用户将数据存储在一个表里,一个数据行拥有一个可选择的键和任意数量的列。由于HBase表是疏松的,用户可以为行定义各种不同的列。HBase主要用于需要随机访问、实时读写的大数据(Big Data)。具体介绍请参考第12章。8)Pig:Pig是一个对大型数据集进行分析、评估的平台。Pig最突出的优势是它的结构能够经受住高度并行化的检验,这个特性使得它能够处理大型的数据集。目前,Pig的底层由一个编译器组成,它在运行的时候会产生一些MapReduce程序序列,Pig的语言层由一种叫做Pig Latin的正文型语言组成。有关Pig的具体内容请参考第14章。9)ZooKeeper:ZooKeeper是一个为分布式应用所设计的开源协调服务。它主要为用户提供同步、配置管理、分组和命名等服务,减轻分布式应用程序所承担的协调任务。ZooKeeper的文件系统使用了我们所熟悉的目录树结构。ZooKeeper是使用Java编写的,但是它支持Java和C两种编程语言。有关ZooKeeper的具体内容请参考第15章。上面讨论的9个项目在本书中都有相应的章节进行详细的介绍。转载地址:http://cljpx.baihongyu.com/
你可能感兴趣的文章
Python中被双下划线包围的魔法方法
查看>>
JAVA核心编程教学
查看>>
Oracle:数据类型对应表
查看>>
洛谷P1349 广义斐波那契数列
查看>>
BZOJ3160 万径人踪灭
查看>>
Okhttp3请求网络开启Gzip压缩
查看>>
pycharm配置mysql数据库连接访问
查看>>
Spring源码学习:第0步--环境准备
查看>>
烂泥:rsync与inotify集成实现数据实时同步更新
查看>>
call & apply
查看>>
学习英语哦
查看>>
第六届蓝桥杯java b组第四题
查看>>
通过TortoiseGIT怎么把本地项目上传到GitHub
查看>>
Python 1 Day
查看>>
Python基础学习笔记(十:二进制位运算)
查看>>
C语言中字符串结束符
查看>>
技术工作者上升到思想,哲学层面也许更好
查看>>
LCD12864使用总结
查看>>
wireshark简明教程
查看>>
EditPlus配置Java编译器
查看>>